
Chat with a Duck
A while ago I published sql-workbench.com and the accompanying blog post called “Using DuckDB-WASM for in-browser Data Engineering”. The SQL Workbench enables its users to analyze local or remote data directly in the browser.
This lowers the bar regarding the infrastructure needed to get started with Data Analysis and Data Engineering. No databases must be installed on servers or developer machines, no data is sent to the internet and SaaS or Cloud providers. The sole interface to the data you want to analyze is SQL.
But what if a user is new in this space, and has no SQL skills yet? Or, if he/she has SQL skills, but wants to query the data without having to understand the data model first?
Enter DuckDB-NSQL#
LLMs (Large Language Models) can be used to generate code from natural language questions. Popular examples include GitHub Copilot, OpenAI’s GPT-4 or Meta’s Code Llama.
DuckDB-NSQL is a Text-to-SQL model created by NumberStation for MotherDuck. It’s hosted on HuggingFace and on Ollama, and can be use with different LLM runtimes. There are also some nice blog posts that are worth a read:
The model was specifically trained for the DuckDB SQL syntax with 200k DuckDB Text-to-SQL pairs, and is based on the Llama-2 7B model.
Bring your own AI#
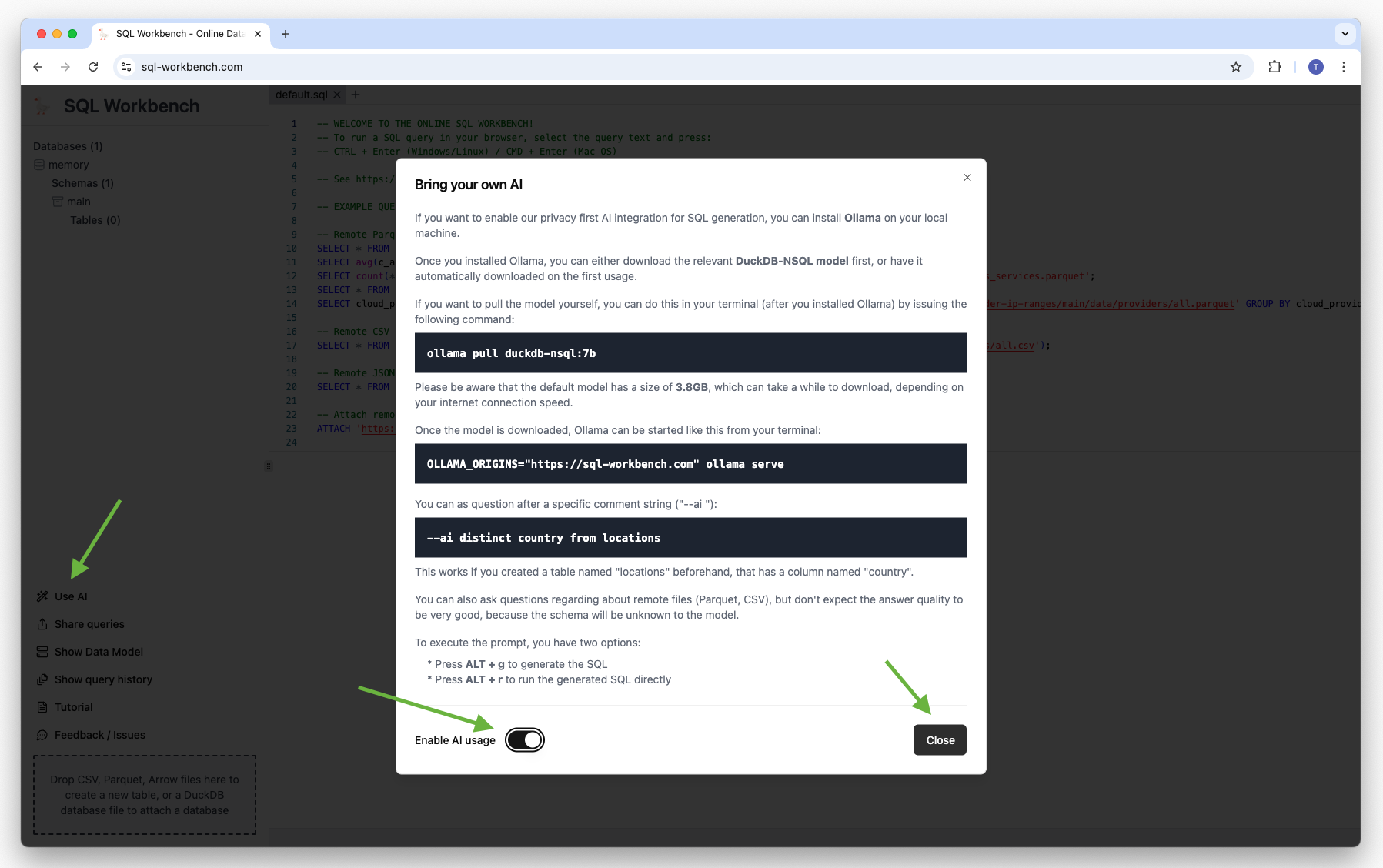
If you want to enable SQL Workbench’s privacy first AI integration for SQL generation, you first have to install Ollama on your local machine.
Once you installed Ollama, you can either download the relevant DuckDB-NSQL model beforehand, or have it automatically downloaded on the first usage.
If you want to pull the model yourself, you can do this in your terminal (after you installed Ollama) by issuing the following command:
ollama pull duckdb-nsql:7bPlease be aware that the default model has a size of 3.8GB, which can take a while to download, depending on your internet connection speed. There are smaller quantized models as well, but be aware that the answer quality might be lower with them.
Once the model is downloaded, Ollama can be started from your terminal:
OLLAMA_ORIGINS="https://sql-workbench.com" ollama serveSetting the OLLAMA_ORIGINS environment variable to https://sql-workbench.com is necessary to enable CORS from the SQL Workbench running in your browser for your locally running Ollama server.
You can enable the AI feature in SQL Workbench:
Then, you can ask your questions after a specific comment string like below:
--ai your natural language questionTo execute the prompt, you have two options:
-
Press ALT + g to generate the SQL
-
Press ALT + r to run the generated SQL directly
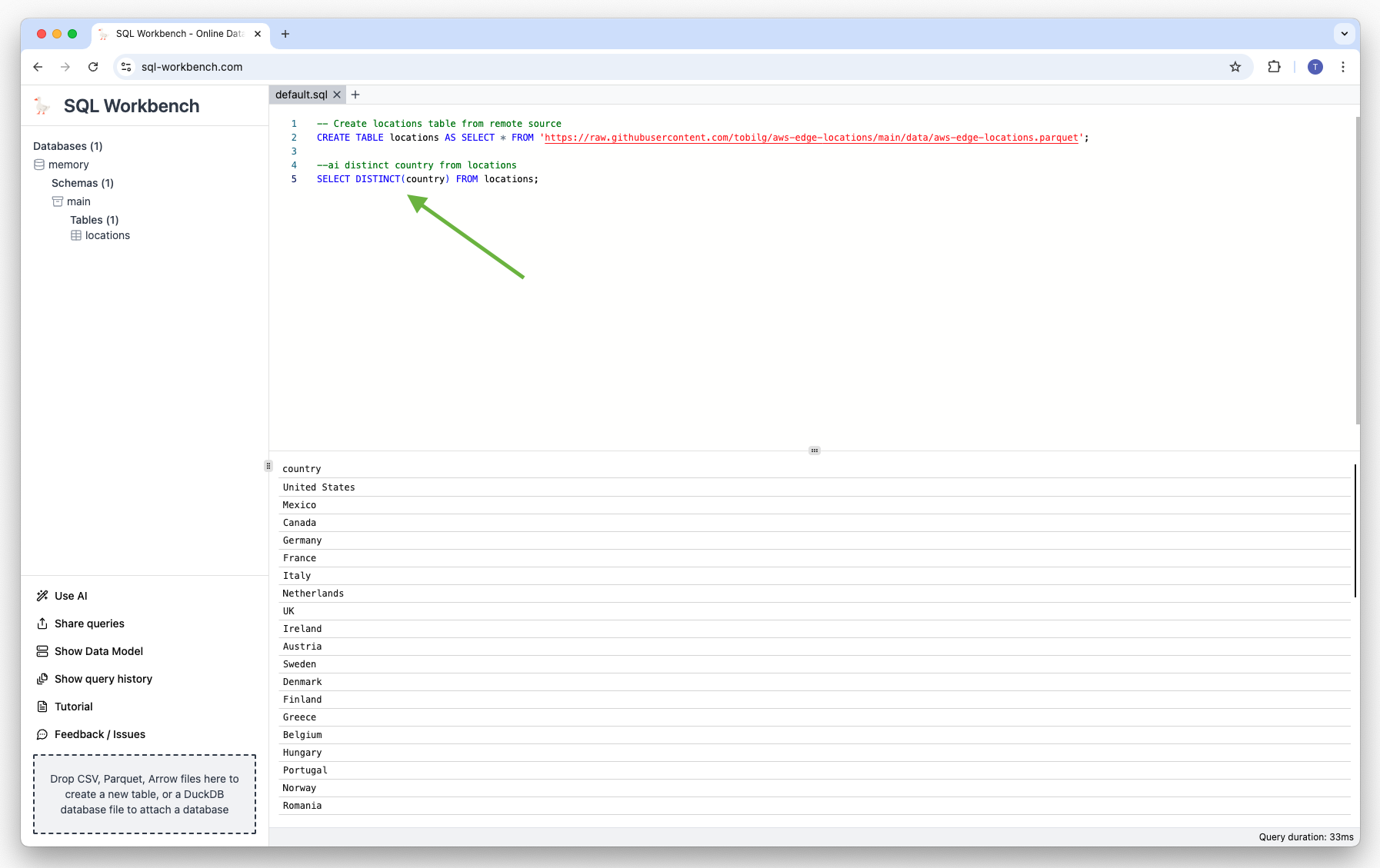
So if you created a table named “locations” beforehand, that has a column named “country”, the following would generate an appropriate SQL:
--ai distinct country from locations
SELECT distinct country FROM locationsThe generated SQL is automatically inserted below the closest prompt comment string. In case you have multiple comment strings in the current SQL Workbench tab, the one closest to the actual cursor position is used.
You can also ask questions regarding about remote files (Parquet, CSV), but don’t expect the answer quality to be very good, because the schema will be unknown to the model.
Explore AWS IAM data with the help of AI#
AWS publishes its Service Authorization Reference documentation, and there’s a Github repository that transforms the published data automatically to Parquet, CSV and JSON data formats every night at 4AM UTC.
Each Parquet file represents a table in a relational data model that looks like this:
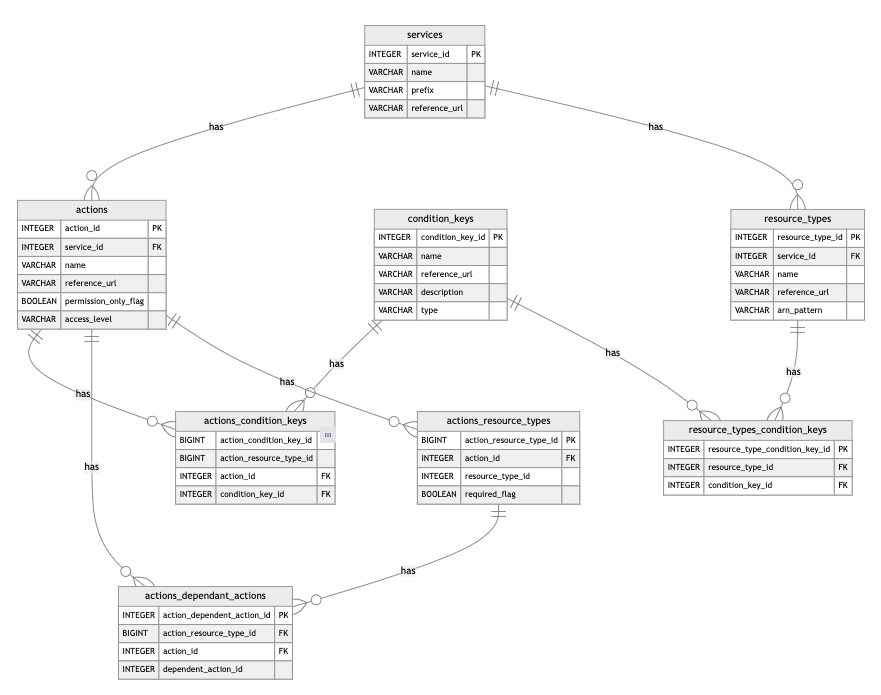
With the help of SQL Workbench and its underlying DuckDB-WASM instance, it’s possible to load the remote data from GitHub into our browser’s memory.
To do this, the following SQL statements need to be executed, either by copy & pasting the code, or automatically via the SQL Workbench’s shareable query feature by clicking on the duck below (this will open in a new browser window/tab, redirected via dub.co):

The create schema will then be used as input for the prompt which is sent to Ollama in the background by the browser.
SQL script#
CREATE TABLE services (
service_id INTEGER PRIMARY KEY,
"name" VARCHAR,
prefix VARCHAR,
reference_url VARCHAR
);
CREATE TABLE actions (
action_id INTEGER PRIMARY KEY,
service_id INTEGER,
"name" VARCHAR,
reference_url VARCHAR,
permission_only_flag BOOLEAN,
access_level VARCHAR,
FOREIGN KEY (service_id) REFERENCES services (service_id)
);
CREATE TABLE condition_keys (
condition_key_id INTEGER PRIMARY KEY,
"name" VARCHAR,
reference_url VARCHAR,
description VARCHAR,
"type" VARCHAR
);
CREATE TABLE resource_types (
resource_type_id INTEGER PRIMARY KEY,
service_id INTEGER,
"name" VARCHAR,
reference_url VARCHAR,
arn_pattern VARCHAR,
FOREIGN KEY (service_id) REFERENCES services (service_id)
);
CREATE TABLE resource_types_condition_keys (
resource_type_condition_key_id INTEGER PRIMARY KEY,
resource_type_id INTEGER,
condition_key_id INTEGER,
FOREIGN KEY (resource_type_id) REFERENCES resource_types (resource_type_id),
FOREIGN KEY (condition_key_id) REFERENCES condition_keys (condition_key_id)
);
CREATE TABLE actions_resource_types (
action_resource_type_id BIGINT PRIMARY KEY,
action_id INTEGER,
resource_type_id INTEGER,
required_flag BOOLEAN,
FOREIGN KEY (action_id) REFERENCES actions (action_id)
);
CREATE TABLE actions_condition_keys (
action_condition_key_id BIGINT PRIMARY KEY,
action_resource_type_id BIGINT,
action_id INTEGER,
condition_key_id INTEGER,
FOREIGN KEY (action_id) REFERENCES actions (action_id),
FOREIGN KEY (condition_key_id) REFERENCES condition_keys (condition_key_id)
);
CREATE TABLE actions_dependant_actions (
action_dependent_action_id INTEGER PRIMARY KEY,
action_resource_type_id BIGINT,
action_id INTEGER,
dependent_action_id INTEGER,
FOREIGN KEY (action_id) REFERENCES actions (action_id),
FOREIGN KEY (action_resource_type_id) REFERENCES actions_resource_types (action_resource_type_id)
);
INSERT INTO services SELECT * FROM 'https://raw.githubusercontent.com/tobilg/aws-iam-data/main/data/parquet/aws_services.parquet';
INSERT INTO resource_types SELECT * FROM 'https://raw.githubusercontent.com/tobilg/aws-iam-data/main/data/parquet/aws_resource_types.parquet';
INSERT INTO condition_keys SELECT * FROM 'https://raw.githubusercontent.com/tobilg/aws-iam-data/main/data/parquet/aws_condition_keys.parquet';
INSERT INTO actions SELECT * FROM 'https://raw.githubusercontent.com/tobilg/aws-iam-data/main/data/parquet/aws_actions.parquet';
INSERT INTO resource_types_condition_keys SELECT * FROM 'https://raw.githubusercontent.com/tobilg/aws-iam-data/main/data/parquet/aws_resource_types_condition_keys.parquet';
INSERT INTO actions_resource_types SELECT * FROM 'https://raw.githubusercontent.com/tobilg/aws-iam-data/main/data/parquet/aws_actions_resource_types.parquet';
INSERT INTO actions_condition_keys SELECT * FROM 'https://raw.githubusercontent.com/tobilg/aws-iam-data/main/data/parquet/aws_actions_condition_keys.parquet';
INSERT INTO actions_dependant_actions SELECT * FROM 'https://raw.githubusercontent.com/tobilg/aws-iam-data/main/data/parquet/aws_actions_dependant_actions.parquet';Example prompts & results#
Prompt
--ai distinct service names that contain 'S3'Result
Prompt
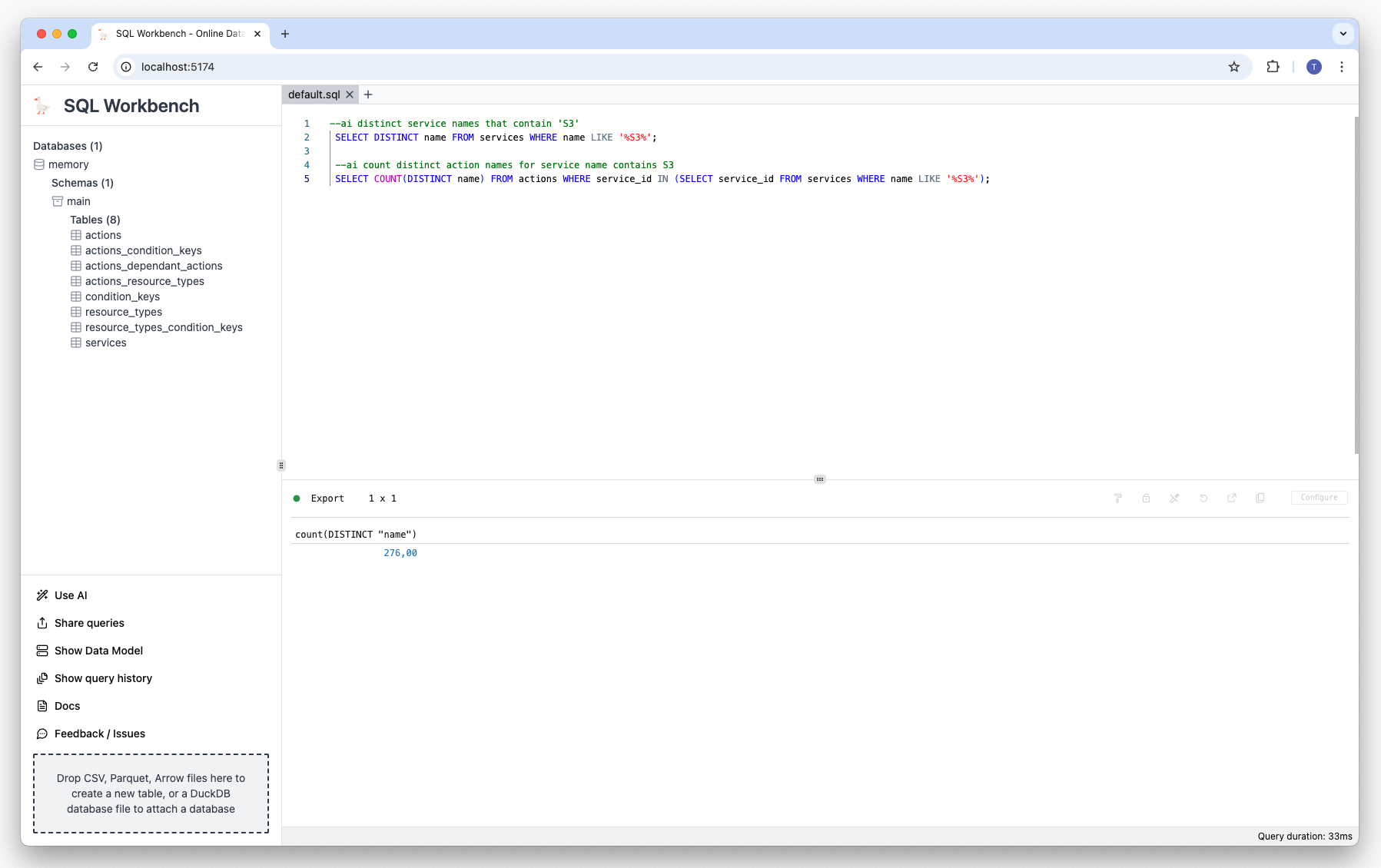
--ai count distinct action names for service name contains S3Result
Prompt
--ai show all 'Write' access level action for service 'Amazon S3'Result
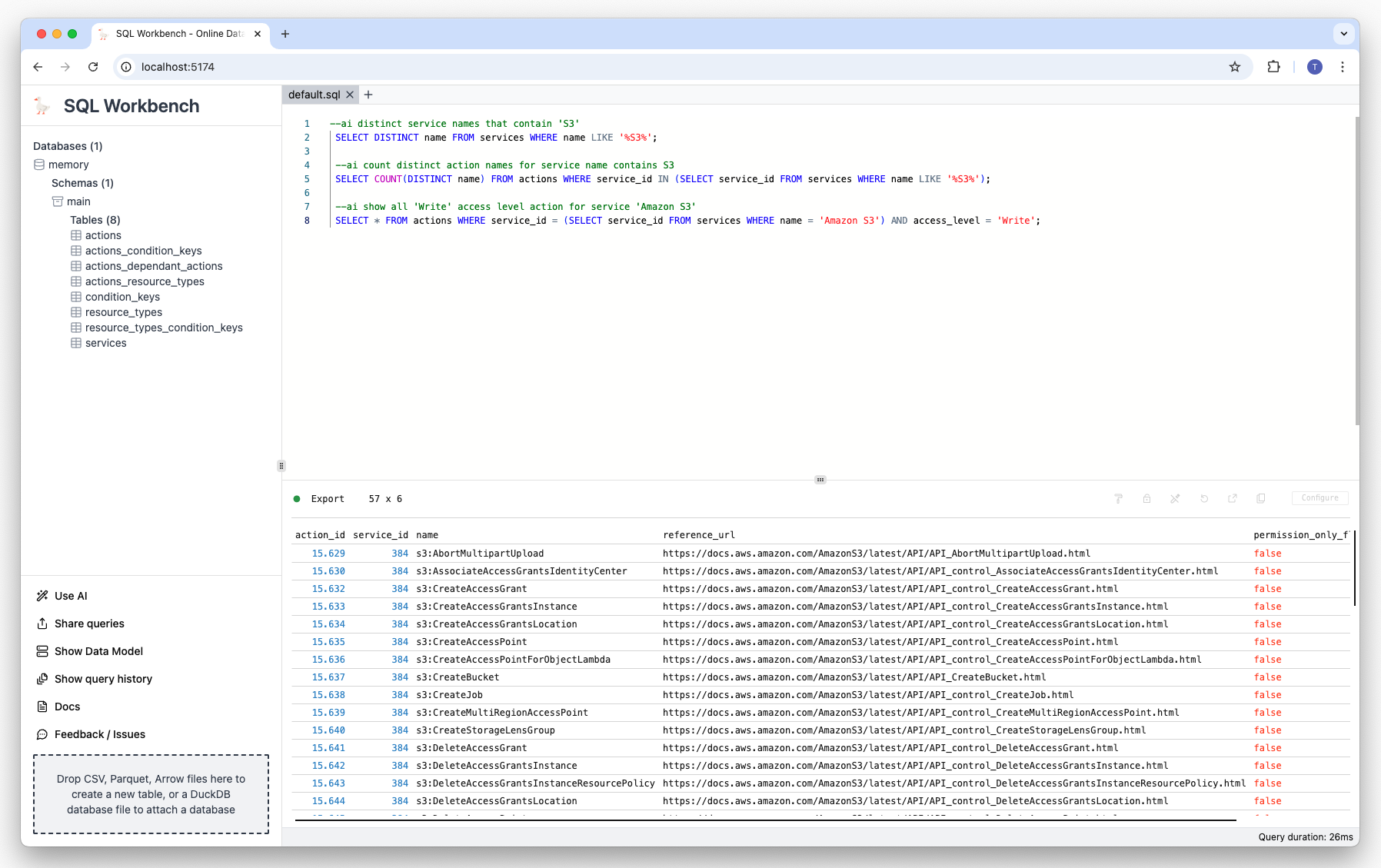
Prompt
--ai first 10 actions for service 'Amazon CloudFront'Result
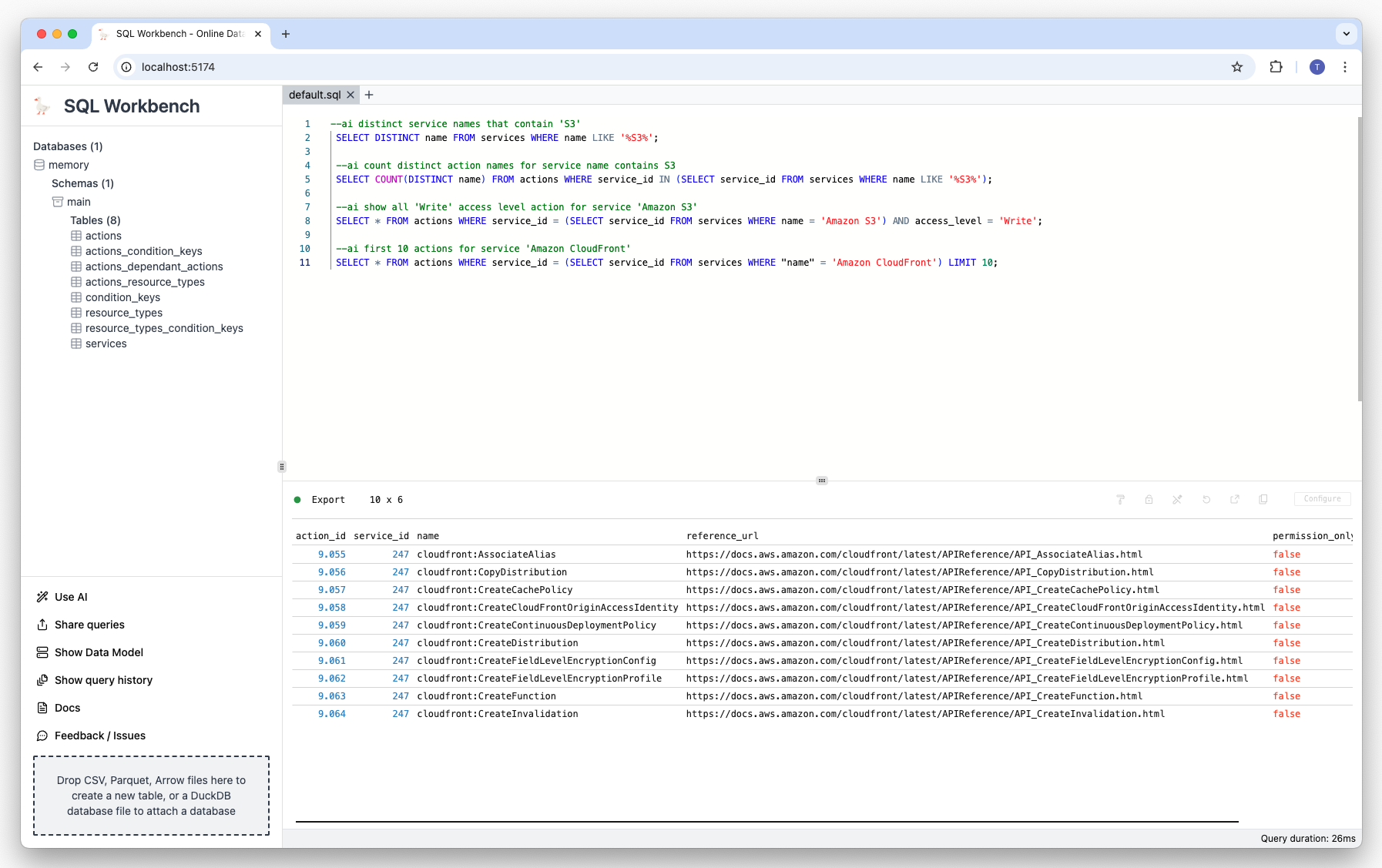
Prompt
--ai service name with least actionsResult
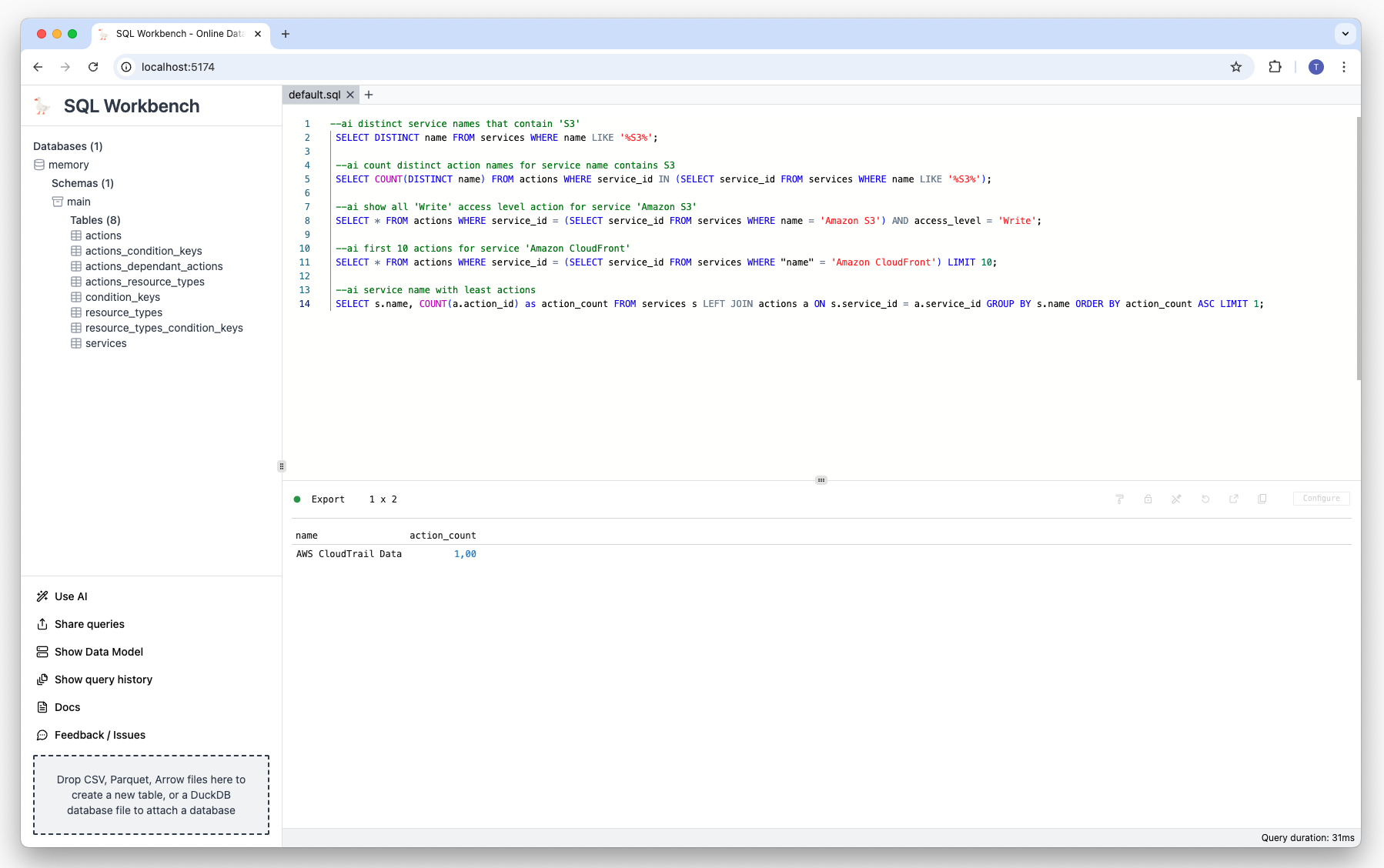
Prompt
--ai service name with most resource typesResult
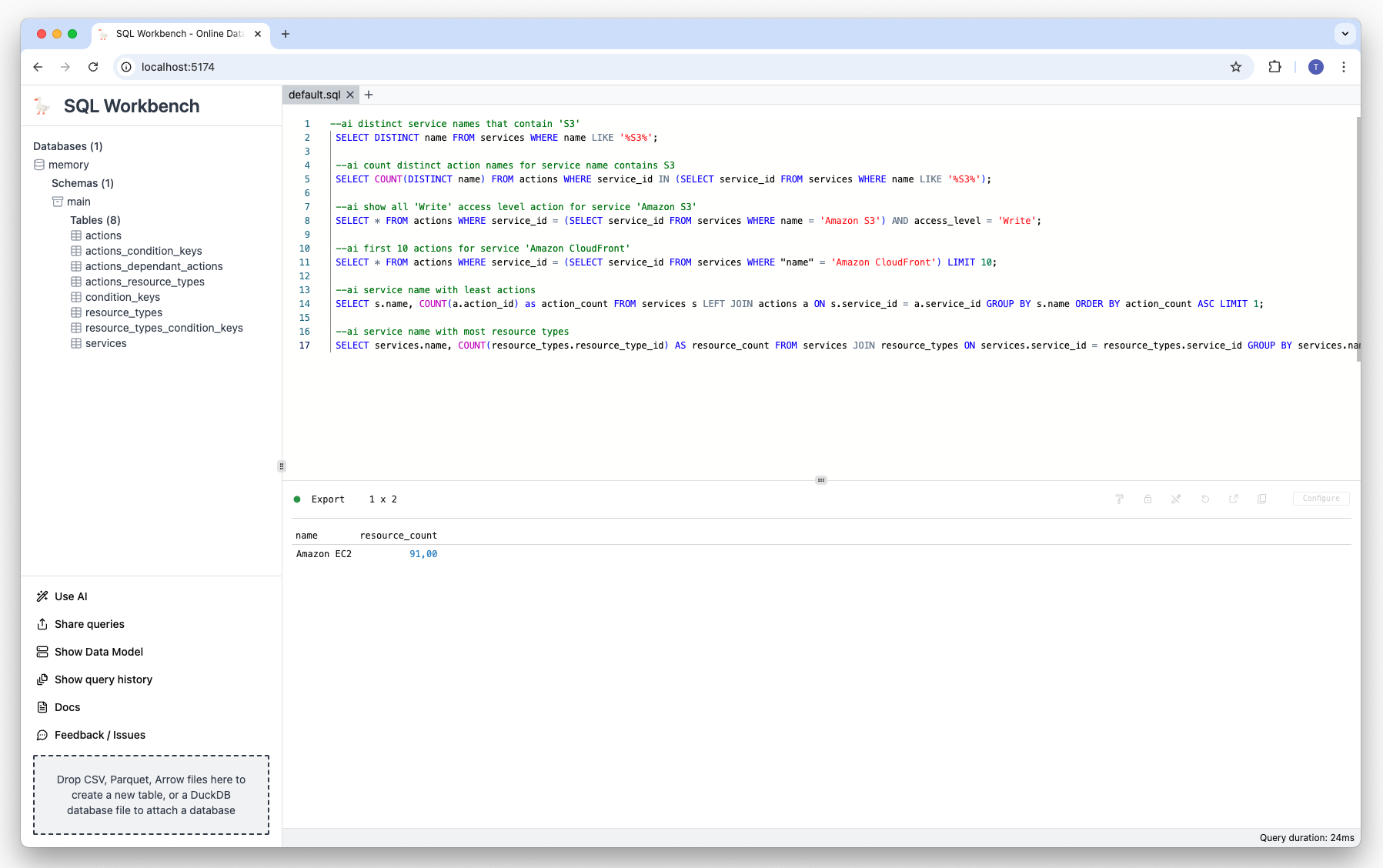
Prompt
--ai count actions names of service 'Amazon S3'Result
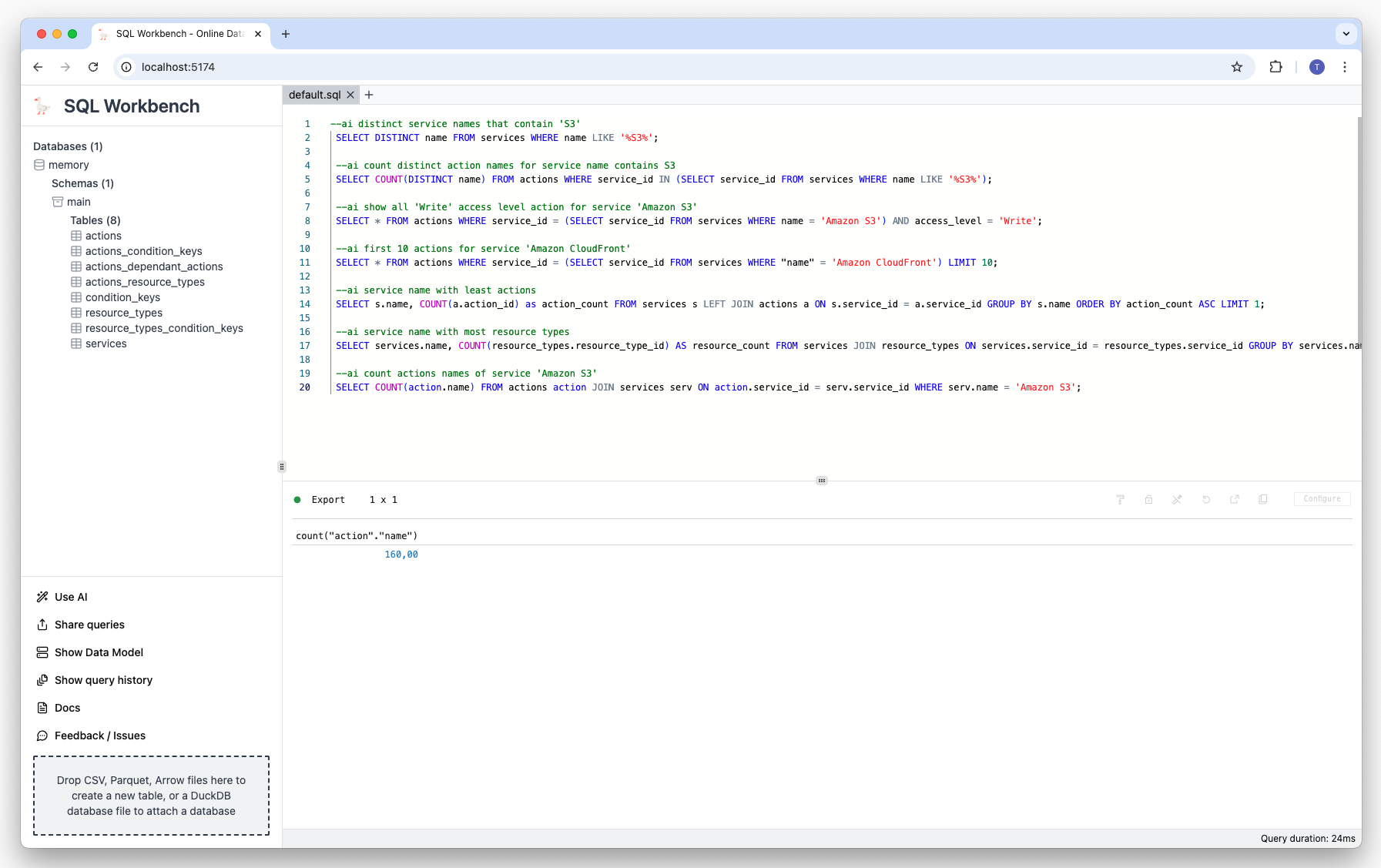
Prompt
--ai top 10 resource types by servicesResult
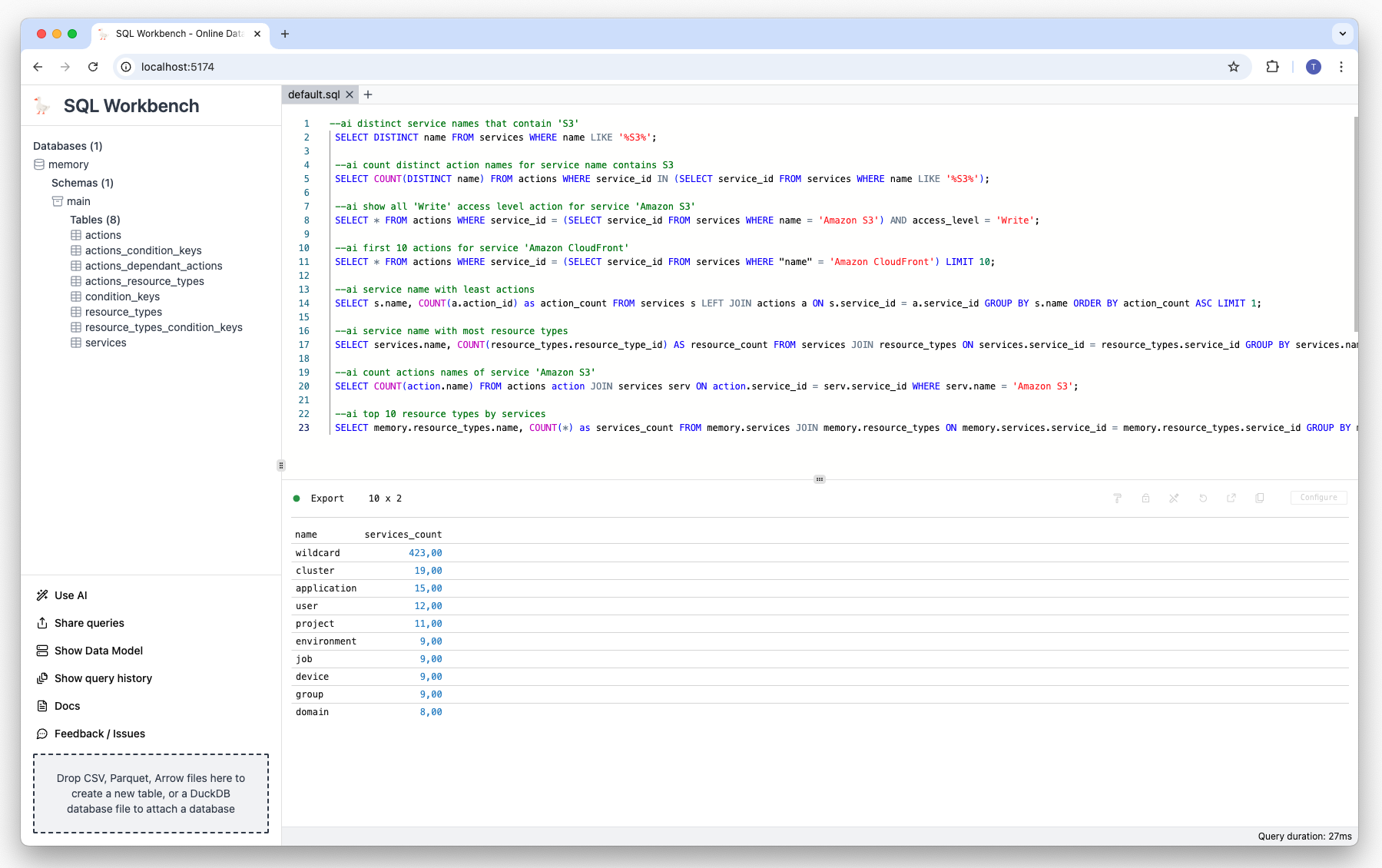
Demo video#
Summary#
Using a locally hosted LLM together with an in-browser SQL Workspace enables a cost-effective and privacy-friendly way to use state of the art tools without needing to rely on third party services.