
Using DuckDB to repartition parquet data in S3
Since release v0.7.1, DuckDB has the ability to repartition data stored in S3 as parquet files by a simple SQL query, which enables some interesting use cases.
Why not use existing AWS services?#
If your data lake lives in AWS, a natural choice for ETL pipelines would be existing AWS services such as Amazon Athena. Unfortunately, Athena has pretty tight limits on the number of partitions that can be written by a single query (only up to 100). You, therefore, would need to create your workaround logic to be able to adhere to the limits, while still being able to do the operations you want. Additionally, Athena in some cases takes several 100ms to even start a query.
This is where DuckDB comes into play because it (theoretically) supports an unlimited amount of Hive partitions, and offers very fast queries on partitioned parquet files.
Use case#
A common pattern to ingest streaming data and store it in S3 is to use Kinesis Data Firehose Delivery Streams, which can write the incoming stream data as batched parquet files to S3. You can use custom S3 prefixes with it when using Lambda processing functions, but by default, you can only partition the data by the timestamp (the timestamp the event reached the Kinesis Data Stream, not the event timestamp!).
So, a few common use cases for data repartitioning could include:
-
Repartitioning the written data for the real event timestamp if it’s included in the incoming data
-
Repartitioning the data for other query patterns, e.g. to support query filter pushdown and optimize query speeds and costs
-
Aggregation of raw or preprocessed data, and storing them in an optimized manner to support analytical queries
We want to be able to achieve this without having to manage our own infrastructure and built-upon services, which is the reason we want to be as serverless as possible.
Solution#
As described before, Amazon Athena only has a partition limit of 100 partitions when writing data. DuckDB doesn’t have this limitation, that’s why we want to be able to use it for repartitioning.
This requires that we can deploy DuckDB in a serverless manner. The choice is to run it in Lambda functions, which can be provisioned with up to 10GB of memory (meaning 6 vCPUs), and a maximum runtime of 900 seconds / 15 minutes. This should be enough for most repartitioning needs, because the throughput from/to S3 is pretty fast. Also, we want to be able to run our repartition queries on flexible schedules, that’s why we’ll use EventBridge Rules with a schedule.
The project can be found at https://github.com/tobilg/serverless-parquet-repartitioner, and just needs to be configured and deployed.
Architecture overview#
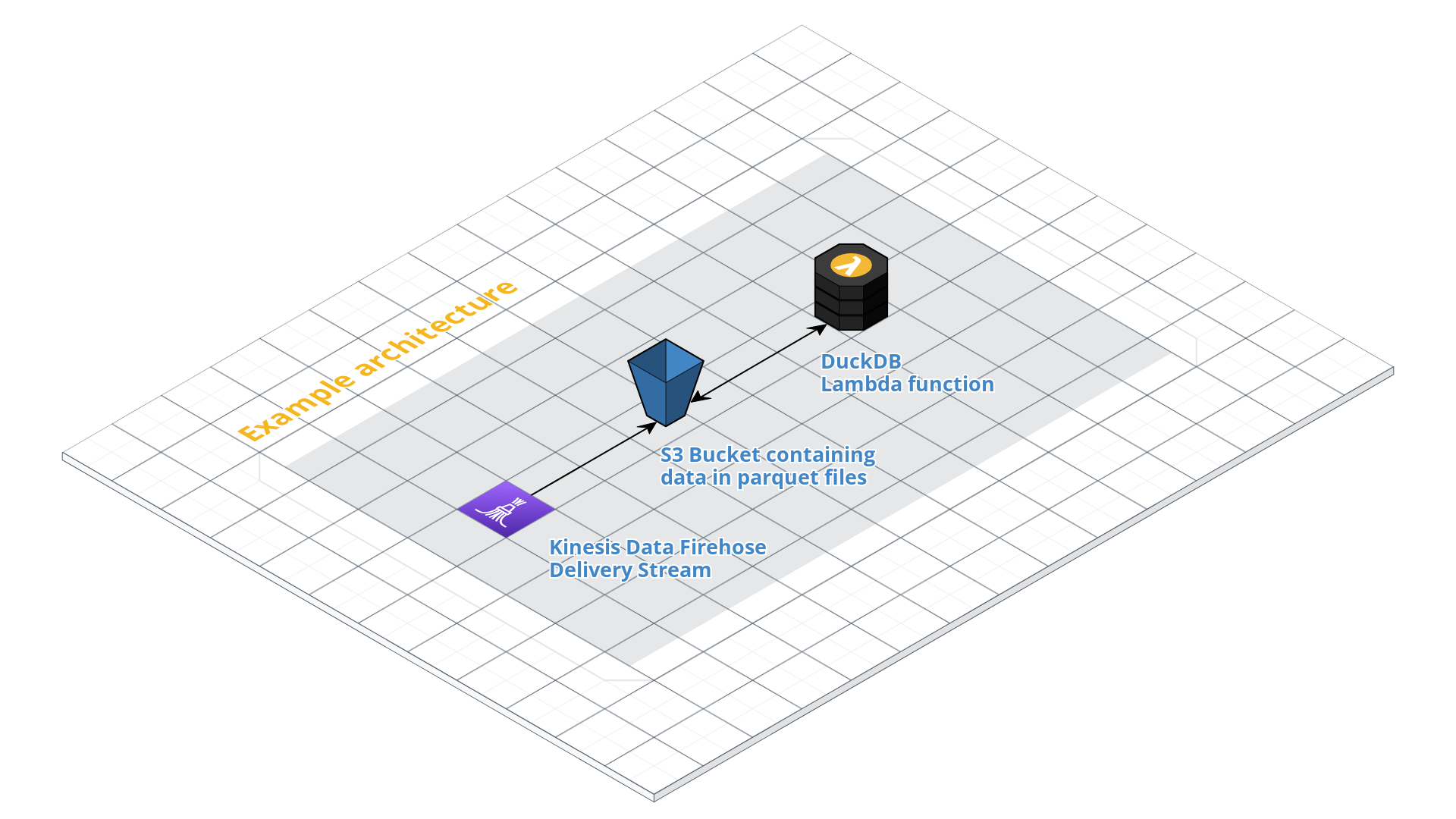
Configuration#
Mandatory configuration settings#
-
S3 bucket name: You need to specify the S3 bucket where the data that you want to repartition resides (e.g.
my-source-bucket) -
Custom repartitioning query: You can write flexible repartitioning queries in the DuckDB syntax. Have a look at the examples in the httpfs extension docs. You need to update this, as the template uses only example values!
Optional configuration settings#
-
S3 region: The AWS region your S3 bucket is deployed to (if different from the region the Lambda function is deployed to)
-
The schedule: The actual schedule on why the Lambda function is run. Have a look at the Serverless Framework docs to find out what the potential settings are.
-
DuckDB memory limit: The memory limit is influenced by the function memory setting (automatically)
-
DuckDB threads count: Optionally set the max thread limit (on Lambda, this is set automatically by the amount of memory the functions has assigned), but with this setting, you can influence how many files are written per partition. If you set a lower thread count than available, this means that the computation will not use all available resources for the sake of being able to set the number of generated files! Ideally, rather align the amount of memory you assign to the Lambda function.
-
Lambda timeout: The maximum time a Lambda function can run is currently 15min / 900sec. This means that if your query takes longer than that, it will be terminated by the underlying Firecracker engine.
Using different source/target S3 buckets#
If you’re planning to use different S3 buckets as sources and targets for the data repartitioning, you need to adapt the iamRoleStatements settings of the function.
Here’s an example with minimal privileges:
iamRoleStatements:
# Source S3 bucket permissions
- Effect: Allow
Action:
- s3:ListBucket
Resource: 'arn:aws:s3:::my-source-bucket'
- Effect: Allow
Action:
- s3:GetObject
Resource: 'arn:aws:s3:::my-source-bucket/*'
# Target S3 bucket permissions
- Effect: Allow
Action:
- s3:ListBucket
- s3:AbortMultipartUpload
- s3:ListMultipartUploadParts
- s3:ListBucketMultipartUploads
Resource: 'arn:aws:s3:::my-target-bucket'
- Effect: Allow
Action:
- s3:GetObject
- s3:PutObject
Resource: 'arn:aws:s3:::my-target-bucket/*'A query for this use case would look like this:
COPY (SELECT * FROM parquet_scan('s3://my-source-bucket/input/*.parquet', HIVE_PARTITIONING = 1)) TO 's3://my-starget-bucket/output' (FORMAT PARQUET, PARTITION_BY (column1, column2, column3), ALLOW_OVERWRITE TRUE);Deployment#
After you cloned this repository to your local machine and cd’ed in its directory, the application can be deployed like this (don’t forget a npm i to install the dependencies!):
$ sls deployThis will deploy the stack to the default AWS region us-east-1. In case you want to deploy the stack to a different region, you can specify a --region argument:
$ sls deploy --region eu-central-1The deployment should take 2-3 minutes.
Checks and manual triggering#
You can manually invoke the deployed Lambda function by running
$ sls invoke -f repartitionDataAfter that, you can check the generated CloudWatch logs by issuing
$ sls logs -f repartitionDataIf you don’t see any DUCKDB_NODEJS_ERROR in the logs, everything ran successfully, and you can have a look at your S3 bucket for the newly generated parquet files.
Costs#
Using this repository will generate costs in your AWS account. Please refer to the AWS pricing docs for the respective services before deploying and running it.
Summary#
We were able to show a possible serverless solution to repartition data that is stored in S3 as parquet files, without limitations imposed by certain AWS services. With the solution shown, we can use plain and simple SQL queries, instead of having to eventually use external libraries etc.
References#
- Serverless parquet repartitioner repo: https://github.com/tobilg/serverless-parquet-repartitioner