



Casual data engineering, or: A poor man's Data Lake in the cloud - Part I
Using AWS Serverless services and DuckDB as near-realtime Data Lake backend infrastructure


In the age of big data, organizations of all sizes are collecting vast amounts of information about their operations, customers, and markets. To make sense of this data, many are turning to data lakes - centralized repositories that store and manage data of all types and sizes, from structured to unstructured. However, building a data lake can be a daunting task, requiring significant resources and expertise.
For enterprises, this often means using SaaS solutions like Snowflake, Dremio, DataBricks or the like. Or, go all-in on the public cloud provider offerings from AWS, Azure and Google Cloud. But what if, as recent studies show, the data sizes aren't as big as commonly thought? Is it really necessary to spend so much money on usage and infrastructure?
In this blog post, we'll walk you through the steps to create a scalable, cost-effective data lake on AWS. Whether you're a startup, a small business, or a large enterprise, this guide will help you unlock the power of big data without breaking the bank (also see the excellent "Big data is dead" blog post by Jordan Tigani).
Modern Data Lake basics
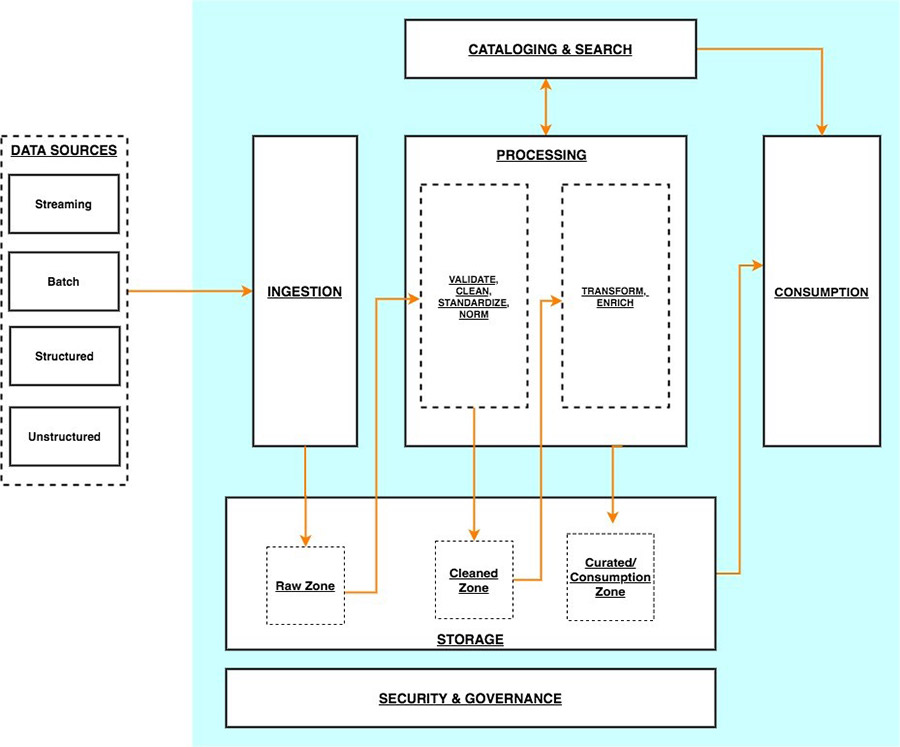
The definition of what a Data Lake is, is probably slightly different depending on whom you're asking (see AWS, Google Cloud, Azure, DataBricks, IBM or Wikipedia). What is common to all these definitions and explanations is that it consists of different layers, such as ingestion, storage, processing and consumption. There can be several other layers as well, like cataloging and search, as well as a security and governance layer.
This is outlined in the excellent AWS article "AWS serverless data analytics pipeline reference architecture", which shall be the basis for this blog post:
Separation of storage & compute
Modern data lakes have revolutionized the way organizations handle big data. A data lake is a central repository that allows organizations to store all types of data, both structured and unstructured, at any scale. The flexibility and scalability of data lakes enable organizations to perform advanced analytics and gain insights that can drive business decisions. One of the key architectural patterns that modern data lakes follow is the separation of storage and compute.
Traditionally, data storage and processing were tightly coupled in data warehouses. However, in modern data lakes, data is stored in a separate layer from the computational layer that processes it. Data storage is handled by a data storage layer, while data processing is done by a compute layer. This approach allows organizations to scale storage and compute independently, enabling them to process vast amounts of data without incurring significant costs.
This has several advantages, which include:
Scalability: It allows organizations to scale each layer independently. The storage layer can be scaled up or down depending on the amount of data being stored, while the compute layer can be scaled up or down depending on the processing requirements.
Cost Savings: Decoupling storage and compute can significantly reduce costs. In traditional data warehouses, organizations must provision sufficient storage and processing power to handle peak loads. This results in underutilized resources during periods of low demand, leading to the wastage of resources and increased costs. In modern data lakes, organizations can store data cheaply and only provision the necessary compute resources when required, leading to significant cost savings.
Flexibility: Organizations can use a range of storage options, including object storage, file storage, and block storage, to store their data. This flexibility allows organizations to choose the most appropriate storage option for their data, depending on factors such as cost, performance, and durability.
Performance: In traditional data warehouses, data is moved from storage to processing, which can be slow and time-consuming, leading to performance issues. In modern data lakes, data is stored in a central repository, and processing is done where the data resides. This approach eliminates the need for data movement, leading to faster processing and improved performance.
Optimized file formats
As an example, Parquet is an open-source columnar storage format for data lakes that is widely used in modern data lakes. Parquet stores data in columns rather than rows, which enables it to perform selective queries faster and more efficiently than traditional row-based storage formats.
Additionally, Parquet supports compression, which reduces storage requirements and improves data processing performance. It's supported by many big data processing engines, including Apache Hadoop, Apache Spark, Apache Drill and many services of public cloud providers, such as Amazon Athena and AWS Glue.
Hive partitioning & query filter pushdown
The so-called "Hive partitioning" is a technique used in data lakes that involves dividing data into smaller, more manageable parts, called partitions, based on specific criteria such as date, time, or location.
Partitioning can help improve query performance and reduce data processing time by allowing users to select only the relevant partitions, rather than scanning the entire dataset.
Query filter pushdown is another optimization technique used in Apache Hive and other services that involves pushing down query filters into the storage layer, allowing it to eliminate irrelevant data before processing the query.
Combining Hive partitioning and query filter pushdown can result in significant performance gains in data processing, as the query filters can eliminate large amounts of irrelevant data at the partition level, reducing the amount of data that needs to be processed. Therefore, Hive partitioning and query filter pushdown are essential techniques for optimizing data processing performance in data lakes.
Repartitioning of data
Repartitioning Parquet data in data lakes is a useful technique that involves redistributing data across partitions based on specific criteria. This technique can help optimize query performance and reduce data shuffling during big data processing.
For instance, if a large amount of data is stored in a single partition, querying that data may take longer than if the data were spread across several partitions. Or, you could write aggregation queries whose output contains much less data, which could improve query speeds significantly.
The use case
Data privacy and GDPR are pretty talked-about topics in recent years. A lot of existing web tracking solutions were deemed as non-compliant, especially in the EU. Thus, individuals and companies had to eventually change their Web Analytics providers, which lead to a rise of new, data privacy-focussing companies in this space (e.g. Fathom Analytics, SimpleAnalytics, and Plausible just to name a few).
The pricing of those providers can get relatively steep quite fast if you have a higher amount of pageviews ($74/mo for 2m at Fathom, €99/mo for 1m at SimpleAnalytics, €89/mo for 2m at Plausible). Also, if you're using a provider, you're normally not owning your data.
So, let's try to build a web tracking and analytics service on AWS for the cheap, while owning our data, adhering to data privacy laws and using scalable serverless cloud services to avoid having to manage infrastructure by ourselves. And have some fun and learn a bit while doing it :-)
High-level architecture
The overall architecture for the outlined use case looks like this:

The details will be described further for each layer in the coming paragraphs. For brevity, the focus lies on the main data processing layers. Other layers, such as cataloging, consumption and security & governance, are eventually handled in other upcoming blog posts.
Serving layer
The serving layer is not a part of the data lake. Its main goal is to serve static assets, such as the tracking JavaScript libraries (those will be covered in more detail in another part of this series), and the 1x1 pixel GIF files that are used as endpoints that the tracking library can push its gathered data to. This is done by sending the JSON payload as URL-encoded query strings.
In our use case, we want to leverage existing AWS services and optimize our costs, while providing great response times. From an architectural perspective, there are many ways we could set up this data-gathering endpoint. Amazon CloudFront is a CDN that has currently over 90 edge locations worldwide, thus providing great latencies compared to classical webservers or APIs that are deployed in one or more regions.
It also has a very generous free tier (1TB outgoing traffic, and 10M requests), and with its real-time logs feature a great and very cost-effective way ($0.01 for every 1M log lines) to set up such an endpoint by just storing a 1x1px GIF with appropriate caching headers, to which the JavaScript tracking library will send its payload to as an encoded query string.
CloudFront can use S3 as a so-called origin (where the assets will be loaded from if they aren't yet in the edge caches), and that's where the static asset data will be located. Between the CloudFront distribution and the S3 bucket, an Origin Access Identity will be created, which enables secure communication between both services and avoids that the S3 bucket needs to be publicly accessible.
To configure CloudFront real-time logs that contain the necessary information, a RealtimeLogConfig needs to be created. This acts as "glue" between the CloudFront distribution and the Kinesis Data Stream that consumes the logs:
CFRealtimeLogsConfig:
Type: AWS::CloudFront::RealtimeLogConfig
Properties:
EndPoints:
- StreamType: Kinesis
KinesisStreamConfig:
RoleArn: !GetAtt 'AnalyticsKinesisDataRole.Arn'
StreamArn: !GetAtt 'AnalyticsKinesisStream.Arn'
Fields:
- timestamp
- c-ip
- sc-status
- cs-uri-stem
- cs-bytes
- x-edge-location
- time-taken
- cs-user-agent
- cs-referer
- cs-uri-query
- x-edge-result-type
- asn
Name: '${self:service}-cdn-realtime-log-config'
# IMPORTANT: This setting make sure we receive all the log lines, otherwise it's just sampled!
SamplingRate: 100
Ingestion layer
The ingestion layer mainly consists of two services: A Kinesis Data Stream, which is the consumer of the real-time logs feature of CloudFront, and a Kinesis Data Firehose Delivery Stream, which will back up the raw data in S3, and also store the data as partitioned parquet files in another S3 bucket. Both S3 buckets are part of the storage layer.
The Kinesis Data Stream (one shard in provisioned mode) provides an ingest capacity of 1 MB/second or 1,000 records/second, for a price of $0.015/hour in us-east-1, and $0.014 per 1M PUT payload units. It forwards the incoming data to the Kinesis Data Firehose Delivery Stream, whose pricing is more complex. The ingestion costs $0.029/GB, the format conversion $0.018/GB, and the dynamic partitioning $0.02/GB. That sums up to $0.067/GB ingested and written to S3, plus the S3 costs of $0.005/1k PUT object calls.
The Kinesis Data Firehose Delivery Stream uses data transformation and dynamic partitioning with a Lambda function, which cleans, transforms and enriches the data so that it can be stored in S3 as parquet files with appropriate Hive partitions.
The Delivery Stream has so-called BufferingHints, which either define from which size (from 1 to 128MB) or in which interval (between 60 to 900 seconds) the data is flushed to S3. The interval defines the minimum latency at which the data gets persisted in the data lake. The Lambda function is part of the processing layer and is discussed below.
The CloudFormation resource definition for the Kinesis Data Firehose Delivery Stream can be found below. It sources its variables from the serverless.yml:
AnalyticsKinesisFirehose:
Type: 'AWS::KinesisFirehose::DeliveryStream'
Properties:
DeliveryStreamName: ${self:custom.kinesis.delivery.name}
DeliveryStreamType: KinesisStreamAsSource
# Source configuration
KinesisStreamSourceConfiguration:
KinesisStreamARN: !GetAtt 'AnalyticsKinesisStream.Arn'
RoleARN: !GetAtt 'AnalyticsKinesisFirehoseRole.Arn'
# Necessary configuration to transfrom and write data to S3 as parquet files
ExtendedS3DestinationConfiguration:
BucketARN: !GetAtt 'CleanedBucket.Arn'
BufferingHints:
IntervalInSeconds: ${self:custom.kinesis.delivery.limits.intervalInSeconds}
SizeInMBs: ${self:custom.kinesis.delivery.limits.sizeInMB}
# This enables logging to CloudWatch for better debugging possibilities
CloudWatchLoggingOptions:
Enabled: True
LogGroupName: ${self:custom.logs.groupName}
LogStreamName: ${self:custom.logs.streamName}
DataFormatConversionConfiguration:
Enabled: True
# Define the input format
InputFormatConfiguration:
Deserializer:
OpenXJsonSerDe:
CaseInsensitive: True
# Define the output format
OutputFormatConfiguration:
Serializer:
ParquetSerDe:
Compression: SNAPPY
WriterVersion: V1
# The schema configuration based on Glue tables
SchemaConfiguration:
RoleArn: !GetAtt 'AnalyticsKinesisFirehoseRole.Arn'
DatabaseName: '${self:custom.glue.database}'
TableName: 'incoming_events'
# Enable dynamic partitioning
DynamicPartitioningConfiguration:
Enabled: True
# Enable Lambda function for pre-processing the Kinesis records
ProcessingConfiguration:
Enabled: True
Processors:
- Type: Lambda
Parameters:
- ParameterName: NumberOfRetries
ParameterValue: 3
- ParameterName: BufferIntervalInSeconds
ParameterValue: 60
- ParameterName: BufferSizeInMBs
ParameterValue: 3
- ParameterName: LambdaArn
ParameterValue: !GetAtt 'ProcessKinesisRecordsLambdaFunction.Arn'
# Enable backups for the raw incoming data
S3BackupMode: Enabled
S3BackupConfiguration:
BucketARN: !GetAtt 'RawBucket.Arn'
BufferingHints:
IntervalInSeconds: ${self:custom.kinesis.delivery.limits.intervalInSeconds}
SizeInMBs: ${self:custom.kinesis.delivery.limits.sizeInMB}
# Disable logging to CloudWatch for raw data
CloudWatchLoggingOptions:
Enabled: false
CompressionFormat: GZIP
Prefix: '${self:custom.prefixes.raw}'
ErrorOutputPrefix: '${self:custom.prefixes.error}'
RoleARN: !GetAtt 'AnalyticsKinesisFirehoseRole.Arn'
RoleARN: !GetAtt 'AnalyticsKinesisFirehoseRole.Arn'
# Define output S3 prefixes
Prefix: '${self:custom.prefixes.incoming}/domain_name=!{partitionKeyFromLambda:domain_name}/event_type=!{partitionKeyFromLambda:event_type}/event_date=!{partitionKeyFromLambda:event_date}/'
ErrorOutputPrefix: '${self:custom.prefixes.error}'
Processing layer
The processing layer consists of two parts, the Lambda function that is used for the dynamic partitioning of the incoming data, and a Lambda function that uses the COPY TO PARTITION BY feature of DuckDB to aggregate and repartition the ingested, enriched and stored page views data.
Data transformation & Dynamic partitioning Lambda
Data transformation is a Kinesis Data Firehose Delivery Stream feature that enables the cleaning, transformation and enrichment of incoming records in a batched manner. In combination with the dynamic partitioning feature, this provides powerful data handling capabilities with the data still being "on stream". When writing data to S3 as parquet files, a schema configuration in the form of a Glue Table needs to be defined as well to make it work (see "Cataloging & search layer" below).
It's necessary to define some buffer configuration for the Lambda function, meaning that you need to specify the time interval of 60 seconds (this will add a max delay of one minute to the stream data), the size in MB (between 0.2 and 3), and the number of retries (3 is the only usable default).
The input coming from the Kinesis Data Firehose Delivery Stream are a base64 encoded strings that contain the loglines coming from the CloudFront distribution:
MTY4MjA4NDI0MS40NjlcdDIwMDM6ZTE6YmYxZjo3YzAwOjhlYjoxOGY4OmExZmI6OWRhZFx0MzA0XHQvaGVsbG8uZ2lmP3Q9cHYmdHM9MTY4MjA4MzgwNDc2OCZ1PWh0dHBzJTI1M0ElMjUyRiUyNTJGbXlkb21haW4udGxkJTI1MkYmaG49bXlkb21haW4udGxkJnBhPSUyNTJGJnVhPU1vemlsbGElMjUyRjUuMCUyNTIwKE1hY2ludG9zaCUyNTNCJTI1MjBJbnRlbCUyNTIwTWFjJTI1MjBPUyUyNTIwWCUyNTIwMTBfMTVfNyklMjUyMEFwcGxlV2ViS2l0JTI1MkY1MzcuMzYlMjUyMChLSFRNTCUyNTJDJTI1MjBsaWtlJTI1MjBHZWNrbyklMjUyMENocm9tZSUyNTJGMTEyLjAuMC4wJTI1MjBTYWZhcmklMjUyRjUzNy4zNiZpdz0xMjkyJmloPTkyNiZ0aT1NeSUyNTIwRG9tYWluJnc9MzQ0MCZoPTE0NDAmZD0yNCZsPWRlLURFJnA9TWFjSW50ZWwmbT04JmM9OCZ0ej1FdXJvcGUlMjUyRkJlcmxpblx0Nzg5XHRIQU01MC1QMlx0MC4wMDFcdE1vemlsbGEvNS4wJTIwKE1hY2ludG9zaDslMjBJbnRlbCUyME1hYyUyME9TJTIwWCUyMDEwXzE1XzcpJTIwQXBwbGVXZWJLaXQvNTM3LjM2JTIwKEtIVE1MLCUyMGxpa2UlMjBHZWNrbyklMjBDaHJvbWUvMTEyLjAuMC4wJTIwU2FmYXJpLzUzNy4zNlx0LVx0dD1wdiZ0cz0xNjgyMDgzODA0NzY4JnU9aHR0cHMlMjUzQSUyNTJGJTI1MkZteWRvbWFpbi50bGQlMjUyRiZobj1teWRvbWFpbi50bGQmcGE9JTI1MkYmdWE9TW96aWxsYSUyNTJGNS4wJTI1MjAoTWFjaW50b3NoJTI1M0IlMjUyMEludGVsJTI1MjBNYWMlMjUyME9TJTI1MjBYJTI1MjAxMF8xNV83KSUyNTIwQXBwbGVXZWJLaXQlMjUyRjUzNy4zNiUyNTIwKEtIVE1MJTI1MkMlMjUyMGxpa2UlMjUyMEdlY2tvKSUyNTIwQ2hyb21lJTI1MkYxMTIuMC4wLjAlMjUyMFNhZmFyaSUyNTJGNTM3LjM2Jml3PTEyOTImaWg9OTI2JnRpPU15JTI1MjBEb21haW4mdz0zNDQwJmg9MTQ0MCZkPTI0Jmw9ZGUtREUmcD1NYWNJbnRlbCZtPTgmYz04JnR6PUV1cm9wZSUyNTJGQmVybGluXHRIaXRcdDMzMjBcbg==
After decoding, the logline is visible and contains the info from the real-time log fields, which are tab-separated and contain newlines:
1682084241.469\t2003:e1:bf1f:7c00:8eb:18f8:a1fb:9dad\t304\t/hello.gif?t=pv&ts=1682083804768&u=https%253A%252F%252Fmydomain.tld%252F&hn=mydomain.tld&pa=%252F&ua=Mozilla%252F5.0%2520(Macintosh%253B%2520Intel%2520Mac%2520OS%2520X%252010_15_7)%2520AppleWebKit%252F537.36%2520(KHTML%252C%2520like%2520Gecko)%2520Chrome%252F112.0.0.0%2520Safari%252F537.36&iw=1292&ih=926&ti=My%2520Domain&w=3440&h=1440&d=24&l=de-DE&p=MacIntel&m=8&c=8&tz=Europe%252FBerlin\t789\tHAM50-P2\t0.001\tMozilla/5.0%20(Macintosh;%20Intel%20Mac%20OS%20X%2010_15_7)%20AppleWebKit/537.36%20(KHTML,%20like%20Gecko)%20Chrome/112.0.0.0%20Safari/537.36\t-\tt=pv&ts=1682083804768&u=https%253A%252F%252Fmydomain.tld%252F&hn=mydomain.tld&pa=%252F&ua=Mozilla%252F5.0%2520(Macintosh%253B%2520Intel%2520Mac%2520OS%2520X%252010_15_7)%2520AppleWebKit%252F537.36%2520(KHTML%252C%2520like%2520Gecko)%2520Chrome%252F112.0.0.0%2520Safari%252F537.36&iw=1292&ih=926&ti=My%2520Domain&w=3440&h=1440&d=24&l=de-DE&p=MacIntel&m=8&c=8&tz=Europe%252FBerlin\tHit\t3320\n
During transformation and enrichment, the following steps are followed:
Validating the source record
Enriching the browser and device data from the user agent string
Determine whether the record was generated by a bot (by user agent string)
Add nearest geographical information based on edge locations
Compute referer
Derive requested URI
Compute UTM data
Get the event type (either a page view or a tracking event)
Build the time hierarchy (year, month, day, event timestamp)
Compute data arrival delays (data/process metrics)
Generate hashes for page view, daily page view and daily visitor ids (later used to calculate page views and visits)
Add metadata with the partition key values (in our case, the partition keys are domain_name, event_date, and event_type), to be able to use the dynamic partitioning feature
The generated JSON looks like this:
{
"result": "Ok",
"error": null,
"data": {
"event_year": 2023,
"event_month": 4,
"event_day": 21,
"event_timestamp": "2023-04-21T13:30:04.768Z",
"arrival_timestamp": "2023-04-21T13:37:21.000Z",
"arrival_delay_ms": -436232,
"edge_city": "Hamburg",
"edge_state": null,
"edge_country": "Germany",
"edge_country_code": "DE",
"edge_latitude": 53.630401611328,
"edge_longitude": 9.9882297515869,
"edge_id": "HAM",
"referer": null,
"referer_domain_name": "Direct / None",
"browser_name": "Chrome",
"browser_version": "112.0.0.0",
"browser_os_name": "Mac OS",
"browser_os_version": "10.15.7",
"browser_timezone": "Europe/Berlin",
"browser_language": "de-DE",
"device_type": "Desktop",
"device_vendor": "Apple",
"device_outer_resolution": "3440x1440",
"device_inner_resolution": "1292x926",
"device_color_depth": 24,
"device_platform": "MacIntel",
"device_memory": 8,
"device_cores": 8,
"utm_source": null,
"utm_campaign": null,
"utm_medium": null,
"utm_content": null,
"utm_term": null,
"request_url": "https://mydomain.tld/",
"request_path": "/",
"request_query_string": "t=pv&ts=1682083804768&u=https%253A%252F%252Fmydomain.tld%252F&hn=mydomain.tld&pa=%252F&ua=Mozilla%252F5.0%2520(Macintosh%253B%2520Intel%2520Mac%2520OS%2520X%252010_15_7)%2520AppleWebKit%252F537.36%2520(KHTML%252C%2520like%2520Gecko)%2520Chrome%252F112.0.0.0%2520Safari%252F537.36&iw=1292&ih=926&ti=My%2520Domain&w=3440&h=1440&d=24&l=de-DE&p=MacIntel&m=8&c=8&tz=Europe%252FBerlin\t789\tHAM50-P2\t0.001\tMozilla/5.0%20(Macintosh;%20Intel%20Mac%20OS%20X%2010_15_7)%20AppleWebKit/537.36%20(KHTML,%20like%20Gecko)%20Chrome/112.0.0.0%20Safari/537.36\t-\tt=pv&ts=1682083804768&u=https%253A%252F%252Fmydomain.tld%252F&hn=mydomain.tld&pa=%252F&ua=Mozilla%252F5.0%2520(Macintosh%253B%2520Intel%2520Mac%2520OS%2520X%252010_15_7)%2520AppleWebKit%252F537.36%2520(KHTML%252C%2520like%2520Gecko)%2520Chrome%252F112.0.0.0%2520Safari%252F537.36&iw=1292&ih=926&ti=My%2520Domain&w=3440&h=1440&d=24&l=de-DE&p=MacIntel&m=8&c=8&tz=Europe%252FBerlin",
"request_bytes": 789,
"request_status_code": 304,
"request_cache_status": "Hit",
"request_delivery_time_ms": 1,
"request_asn": 3320,
"request_is_bot": 0,
"event_name": null,
"event_data": null,
"page_view_id": "f4e1939bc259131659b00cd5f73e55a5bed04fbfa63f095b561fd87009d0a228",
"daily_page_view_id": "7c82d13036aa2cfe04720e0388bb8645eb90de084bd50cf69356fa8ec9d8b407",
"daily_visitor_id": "9f0ac3a2560cfa6d5c3494e1891d284225e15f088414390a40fece320021a658",
"domain_name": "mydomain.tld",
"event_date": "2023-04-21",
"event_type": "pageview"
},
"metadata": {
"partitionKeys": {
"domain_name": "mydomain.tld",
"event_date": "2023-04-21",
"event_type": "pageview"
}
}
}
Then, the following steps are done by the Lambda function:
Encode the JSON stringified records in base64 again
Return them to the Kinesis Data Firehose Delivery Stream, which will then persist the data based on the defined prefix in the S3 bucket for incoming data.
Aggregation Lambda
As the ingested data contains information on a single request level, it makes sense to aggregate the data so that queries can be run optimally, and query response times are reduced.
The aggregation Lambda function is based on tobilg/serverless-parquet-repartitioner, which also has an accompanying blog post that explains in more detail how the DuckDB Lambda Layer can be used to repartition or aggregate existing data in S3.
The Lambda function is scheduled to run each night at 00:30AM, which makes sure that all the Kinesis Firehose Delivery Stream output files of the last day have been written to S3 (this is because the maximum buffer time is 15 minutes).
When it runs, it does three things:
Create a session aggregation, that derives the session information and whether single requests were bounces or not
Calculate the pageviews and visitor numbers, broken down by several dimensions which are later needed for querying (see
statstable below)Store the extraction of the event data separately, newly partitioned by
event_nameto speed up queries
The queries can be inspected in the accompanying repository to get an idea about the sophisticated query patterns DuckDB supports.
Storage layer
The storage layer consists of three S3 buckets, where each conforms to a zone outlined in the reference architecture diagram (see above):
A raw bucket, where the raw incoming data to the Kinesis Firehose Delivery Stream is backed up to (partitioned by
event_date)A cleaned bucket, where the data is stored by the Kinesis Firehose Delivery Stream (partitioned by
domain_name,event_dateandevent_type)A curated bucket, where the aggregated pageviews and visitors data are stored (partitioned by
domain_nameandevent_date), as well as the aggregated and filtered events (partitioned bydomain_name,event_dateandevent_name)
Cataloging & search layer
The Kinesis Data Firehose Delivery Stream needs a Glue table that holds the schema of the parquet files to be able to produce them (incoming_events table). The stats and the events tables are aggregated daily from the base incoming_events table via cron jobs scheduled by Amazon EventBridge Rules at 00:30 AM.
incoming_events table
This table stores the events that are the result of the data transformation and dynamic partitioning Lambda function. The schema for the table incoming_events looks like this:
| Column name | Data type | Is partition key? | Description |
| domain_name | string | yes | The domain name |
| event_date | string | yes | The date of the event (YYYY-MM-DD), as string |
| event_type | string | yes | The type of the event (pageview or track) |
| event_year | int | no | The year of the event_date (YYYY) |
| event_month | int | no | The month of the event (MM) |
| event_day | int | no | The day of the event (DD) |
| event_timestamp | timestamp | no | The exact event timestamp |
| arrival_timestamp | timestamp | no | The exact timestamp when the event arrived in the Kinesis Data Stream |
| arrival_delay_ms | int | no | The difference between event_timestamp and arrival_timestamp in milliseconds |
| edge_city | string | no | The name of the edge city (all edge location info is derived from the x-edge-location field in the logs) |
| edge_state | string | no | The state of the edge location |
| edge_country | string | no | The country of the edge location |
| edge_country_code | string | no | The country code of the edge location |
| edge_latitude | float | no | The latitude of the edge location |
| edge_longitude | float | no | The longitude of the edge location |
| edge_id | string | no | The original id of the edge location |
| referrer | string | no | The referrer |
| referrer_domain_name | string | no | The domain name of the referrer |
| browser_name | string | no | The name of the browser |
| browser_version | string | no | The version of the browser |
| browser_os_name | string | no | The OS name of the browser |
| browser_os_version | string | no | The OS version of the browser |
| browser_timezone | string | no | The timezone of the browser |
| browser_language | string | no | The language of the browser |
| device_type | string | no | The device type |
| device_vendor | string | no | The device vendor |
| device_outer_resolution | string | no | The outer resolution of the device |
| device_inner_resolution | string | no | The inner resolution of the device |
| device_color_depth | int | no | The color depth of the device |
| device_platform | string | no | The platform of the device |
| device_memory | float | no | The memory of the device (in MB) |
| device_cores | int | no | The number of cores of the device |
| utm_source | string | no | Identifies which site sent the traffic |
| utm_campaign | string | no | Identifies a specific product promotion or strategic campaign |
| utm_medium | string | no | Identifies what type of link was used, such as cost per click or email |
| utm_content | string | no | Identifies what specifically was clicked to bring the user to the site |
| utm_term | string | no | Identifies search terms |
| request_url | string | no | The full requested URL |
| request_path | string | no | The path of the requested URL |
| request_query_string | string | no | The query string of the requested URL |
| request_bytes | int | no | The size of the request in bytes |
| request_status_code | int | no | The HTTP status code of the request |
| request_cache_status | string | no | The CloudFront cache status |
| request_delivery_time_ms | int | no | The time in ms it took for CloudFront to complete the request |
| request_asn | int | no | The ASN of the requestor |
| request_is_bot | int | no | If the request is categorized as a bot, the value will be 1, if not 0 |
| event_name | string | no | The name of the event for tracking events |
| event_data | string | no | The stringified event payload for tracking events |
| page_view_id | string | no | The unique pageview id |
| daily_page_view_id | string | no | The unique daily pageview id |
| daily_visitor_id | string | no | The unique daily visitor id |
stats table
The pageviews and visitor aggregation table. Its schema looks like this:
| Column name | Data type | Is partition key? | Description |
| domain_name | string | yes | The domain name |
| event_date | string | yes | The date of the event (YYYY-MM-DD), as string |
| event_hour | int | no | The hour part of the event timestamp |
| edge_city | string | no | The name of the edge city (all edge location info is derived from the x-edge-location field in the logs) |
| edge_country | string | no | The country of the edge location |
| edge_latitude | float | no | The latitude of the edge location |
| edge_longitude | float | no | The longitude of the edge location |
| referrer_domain_name | string | no | The domain name of the referrer |
| browser_name | string | no | The name of the browser |
| browser_os_name | string | no | The OS name of the browser |
| device_type | string | no | The device type |
| device_vendor | string | no | The device vendor |
| utm_source | string | no | Identifies which site sent the traffic |
| utm_campaign | string | no | Identifies a specific product promotion or strategic campaign |
| utm_medium | string | no | Identifies what type of link was used, such as cost per click or email |
| utm_content | string | no | Identifies what type of link was used, such as cost per click or email |
| utm_term | string | no | Identifies search terms |
| request_path | string | no | The path of the requested URL |
| page_view_cnt | int | no | The number of page views |
| visitor_cnt | int | no | The number of daily visitors |
| bounces_cnt | int | no | The number of bounces (visited only one page) |
| visit_duration_sec_avg | int | no | The average duration of a visit (in seconds) |
events table
The schema for the table events looks like this:
| Column name | Data type | Is partition key | Description |
| domain_name | string | yes | The domain name |
| event_date | string | yes | The date of the event (YYYY-MM-DD), as string |
| event_name | string | yes | The name of the event for tracking events |
| event_timestamp | timestamp | no | The exact event timestamp |
| edge_city | string | no | The name of the edge city (all edge location info is derived from the x-edge-location field in the logs) |
| edge_country | string | no | The country of the edge location |
| edge_latitude | float | no | The latitude of the edge location |
| edge_longitude | float | no | The longitude of the edge location |
| request_path | string | no | The path of the requested URL |
| page_view_id | string | no | The unique pageview id |
| daily_visitor_id | string | no | The unique daily visitor id |
| event_data | string | no | The stringified event payload for tracking events |
Consumption layer
The consumption layer will be part of another blog post in this series. Stay tuned! Until it's released, you can have a look at tobilg/serverless-duckdb to get an idea of how the data could potentially be queried in a serverless manner.
Wrapping up
In this article, you learned some basic principles of modern data lakes in the introduction. After that, it described how to build a serverless, near-realtime data pipeline leveraging AWS services and DuckDB on these principles, by the example of a web analytics application.
The example implementation of this article can be found on GitHub at ownstats/ownstats. Feel free to open an issue in case something doesn't work as expected, or if you'd like to add a feature request.
The next posts in this series will be
Part II: Building a lightweight JavaScript library for the gathering of web analytics data
Part III: Consuming the gathered web analytics data by building a serverless query layer
Part IV: Building a frontend for web analytics data